I recall a conversation with a data architect who likened managing data systems to running a restaurant kitchen. On one side, you have the line cooks—executing orders with lightning speed and precision. These are the transactional systems. On the other, you have the executive chef poring over supply chain reports, analyzing food costs, and planning next season’s menu. This is the analytical side. For decades, these two functions have operated in separate kitchens, connected only by a slow-moving waiter—the ETL process—running back and forth. This separation creates a “data-value gap,” a delay between an event happening and the business gaining insight from it.
 Source: image generated with gpt4o
Source: image generated with gpt4o
But what if the line cook and the executive chef could work off the same, live inventory sheet? This is the promise of HTAP (Hybrid Transactional/Analytical Processing), an architectural paradigm that reframes the old “either/or” question. It suggests you can, and should, have both transactional and analytical capabilities in a single, unified system. This article will explore this fundamental shift, moving from the traditional data divide to the unified, real-time future HTAP enables.
The Old Divide: A Quick Refresher on OLTP and OLAP
To truly appreciate the transformative shift HTAP represents, it helps to understand the historical context. The separation of duties in data architecture wasn’t accidental; it was a necessary compromise based on the technological constraints of the time. This led to the emergence of two distinct types of systems, each optimized for a specific purpose: OLTP (for company operations) and OLAP (for data analysis).
The traditional bridge between these two disparate worlds has been ETL (Extract, Transform, Load). Data is periodically extracted from the OLTP system, transformed into a format suitable for analysis, and then loaded into the OLAP data warehouse. This ETL process has long been the problematic middleman—often complex, costly, and, most importantly, slow. It creates the inherent latency that prevents true, real-time analysis, contributing significantly to the data-value gap.
OLTP (Online Transactional Processing)
It’s the engine that runs the day-to-day business operations. As Oracle describes, these systems are engineered for a large number of users conducting a high volume of short, atomic transactions. Think of common interactions like an e-commerce checkout, a bank withdrawal, or a flight booking. Their architecture is typically row-oriented, highly optimized for quickly writing and updating single records while rigorously ensuring data integrity. The paramount priority here is speed and reliability for operational efficiency.
OLAP (Online Analytical Processing)
It’s the system designed to understand the business. It specializes in handling complex queries over vast amounts of historical data to uncover trends, patterns, and insights. As Oracle further explains, OLAP systems are often columnar in nature, a structure highly efficient for aggregating large datasets required for reports like quarterly sales analysis or customer segmentation. The priority here is analytical power and flexibility, not individual transactional speed.
Enter HTAP: Unifying the Two Worlds
The limitations of the ETL-bound model have become increasingly apparent in a modern economy that demands instant answers and real-time responsiveness. This is precisely where HTAP steps in. At its core, HTAP systems are engineered to seamlessly process both high-throughput transactional workloads and complex analytical queries on the same data, in real-time.
The core promise of HTAP is profound: it fundamentally eliminates the need for separate systems and the cumbersome, delayed data movement between them. As experts at PingCAP highlight, this architectural shift allows analytics to be performed on the freshest possible data, effectively closing the crucial data-value gap. Instead of analyzing what happened yesterday or last week, businesses can now analyze what is happening right now. This transforms analytics from a reactive, report-generating function into a proactive, operational capability.
The Architecture of ‘And’: How HTAP Actually Works
This remarkable unification isn’t magic; it’s the result of clever engineering that combines the best characteristics of both transactional and analytical systems. HTAP platforms are built on several key architectural principles that allow them to serve two masters effectively, ensuring both workloads can coexist without compromising performance.
Distributed Foundation
Most modern HTAP platforms are built upon a distributed architecture. This design is crucial as it allows them to scale horizontally, meaning more nodes can be added to handle increasing loads for both transactions and analytics. Furthermore, a distributed foundation provides inherent resilience and high availability, which are absolutely critical for operational systems that cannot afford downtime.
Hybrid Storage
This is often considered the “secret sauce” of HTAP. These systems employ a sophisticated hybrid storage model. They maintain a row-based store, meticulously optimized for fast transactional writes and rapid point lookups, frequently held in-memory for maximum speed. Simultaneously, they maintain a synchronized columnar store, specifically optimized for the large-scale scans and aggregations required by analytical queries. Data is typically replicated from the row store to the column store in near real-time, ensuring that analytics are always current and reflect the latest operational state.
Smart Query Processing
An intelligent query optimizer sits at the heart of an HTAP system, acting as its brain. It can expertly distinguish between a short, latency-sensitive transactional query and a long, resource-intensive analytical one. As described in various comparisons of HTAP approaches, this optimizer is smart enough to route the query to the appropriate engine or storage layer. For instance, a request to “find customer by ID” will efficiently hit the fast row store, while a query to “calculate average sales by region for the last quarter” will be intelligently directed to the efficient columnar store. This ensures both workload types can coexist harmoniously without stepping on each other’s toes or degrading performance.
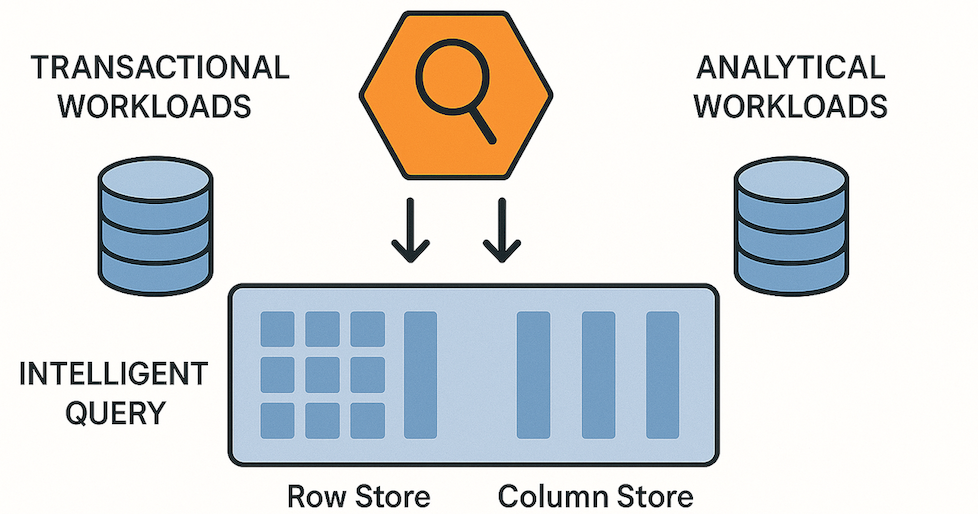 HTAP architecture diagram, composed by a single data layer with separate (or integrated) row and column stores, with an intelligent query optimizer directing traffic. Source: generated with gpt4o.
HTAP architecture diagram, composed by a single data layer with separate (or integrated) row and column stores, with an intelligent query optimizer directing traffic. Source: generated with gpt4o.
The Tangible Benefits of a Unified System
Moving to a unified HTAP architecture isn’t merely an elegant engineering exercise; it delivers concrete, measurable business advantages that are exceedingly difficult to achieve with traditional bifurcated systems.
1. Real-Time Insights: This is arguably the headline benefit and the most compelling reason for HTAP adoption. When analytics can run directly on live transactional data, it unlocks an entirely new class of applications and business capabilities. For example, financial services can perform instant fraud detection on a transaction as it happens, not minutes or hours later. E-commerce platforms can implement dynamic pricing based on real-time demand and inventory levels. Supply chains can manage inventory with up-to-the-second accuracy, proactively preventing costly stockouts or wasteful overages.
2. Simplified Architecture: By eliminating the need for separate data warehouses and complex ETL pipelines, HTAP drastically reduces overall architectural complexity. As SingleStore highlights in its discussion of HTAP, this simplification directly translates to lower operational overhead. There are fewer distinct systems to manage, monitor, and maintain, which frees up valuable engineering resources to focus on high-value-generating activities rather than tedious data plumbing.
3. Reduced Data Duplication: A single, unified system inherently means a single source of truth for your data. This significantly reduces data redundancy, which in turn lowers storage costs. More importantly, it dramatically improves data governance and consistency. There’s no longer a risk of the analytics team and the operations team reporting different numbers because their underlying data is out of sync. Everyone works from the same, current dataset.
A Glimpse into the HTAP Technology Landscape
The HTAP market is vibrant, innovative, and rapidly growing, with several key players offering distinct approaches to solving the hybrid workload problem. This is a brief survey, not an exhaustive comparison, meant to illustrate the diversity and maturity of the landscape.
-
SingleStore (formerly MemSQL): A pioneer in the space, SingleStore leverages a distributed, in-memory, and tiered storage architecture. It positions itself as a high-performance, all-in-one database designed for data-intensive applications that require both fast transactions and real-time analytics by integrating row and column stores within a unified workspace.
-
TiDB: With its origins in the open-source community, TiDB is a cloud-native, distributed SQL database that is highly compatible with MySQL. Its architecture explicitly separates storage (using TiKV for transactional data) from compute and features a columnar storage engine (TiFlash) for analytics, allowing it to serve both workloads efficiently.
-
CockroachDB / YugabyteDB: These are leading distributed SQL databases built primarily for strong transactional consistency, resilience, and global distribution. They are increasingly enhancing their core transactional engines with stronger analytical capabilities, evolving into powerful HTAP contenders by adding columnar indexing and improved query execution for analytical queries.
-
Cloud Provider Solutions (e.g., Google Cloud AlloyDB): The entry of major cloud providers into this space validates the growing importance of the HTAP market. Solutions like Google Cloud’s AlloyDB for PostgreSQL combine a highly optimized transactional engine with a columnar accelerator to significantly boost analytical query performance directly on operational PostgreSQL data.
Below you can find a table with a summary of the 3 engines:
| Technology | Primary Strength | Architecture Approach |
|---|---|---|
| SingleStore | High-performance, in-memory speed | Unified workspace with row/column stores |
| TiDB | MySQL compatibility, cloud-native | Decoupled storage with row/column replicas |
| CockroachDB | Geo-distribution, resilience | Evolving analytical features on a Tx core |
| AlloyDB | PostgreSQL compatibility, cloud integration | Transactional engine + columnar accelerator |
The Real-World Hurdles: Challenges of HTAP Implementation
Like any powerful and transformative technology, HTAP is not a silver bullet that solves all problems automatically. Adopting it requires careful consideration of both technical and organizational challenges. It truly represents a paradigm shift, and such shifts are rarely seamless.
Technical Challenges
-
Consistency vs. Performance: There is an inherent tension between providing the strict consistency guarantees required for mission-critical transactions and the high throughput and low latency needed for analytics. Teams must thoroughly understand the consistency model of their chosen HTAP system and the trade-offs involved in specific use cases.
-
Workload Isolation: A primary concern for any HTAP system is preventing a massive, resource-intensive analytical query from consuming all available resources and, consequently, slowing down critical transactional workloads. Modern HTAP systems incorporate sophisticated workload management features, but these must be correctly configured, monitored, and managed to ensure optimal performance for both types of operations.
-
Scalability & Cost: While HTAP systems are designed to scale, doing so effectively requires deep expertise in distributed systems. Costs can also escalate rapidly if resource usage is not properly governed, especially in dynamic cloud environments where resources are provisioned on demand.
Organizational & Cultural Challenges
-
Skill Gap: The concept of a single database serving all purposes can be foreign to teams accustomed to highly specialized roles. Database administrators (DBAs) focused on OLTP and data engineers focused on OLAP may require significant retraining to effectively manage a single system that serves two very different, demanding purposes.
-
Cultural Resistance: Perhaps the biggest hurdle is overcoming the deeply ingrained “this is how we’ve always done it” mentality. Convincing separate database and analytics teams to trust, adopt, and collaborate effectively on a single, shared platform requires a significant cultural shift, strong leadership, and clear communication of the benefits.
-
Vendor Lock-in & Stack Complexity: Choosing an HTAP solution means introducing a new, highly critical component into your core technology stack. While HTAP aims to simplify, the initial migration to—and potentially away from—these platforms can be a complex and resource-intensive endeavor, and teams must be aware of potential vendor lock-in.
Conclusion
HTAP represents a fundamental rethinking of data architecture. It moves us decisively away from the siloed, high-latency world of separate OLTP and OLAP systems and toward a unified, real-time model. It reframes the debate from a restrictive choice between transactional and analytical systems to a question of how to best leverage them together for maximum business impact.
This is more than just a technological evolution; it is a profound business enabler. By providing immediate access to insights derived from live, operational data, HTAP empowers a new class of intelligent, data-driven applications that can react instantly to the world as it changes. The pressing question for data leaders and architects is no longer “analytical or transactional?” but rather, “how quickly can we modernize our data stack to fully leverage the transformative power of both?”