I met the founders of Argilla (company bought by huggingface) few years ago, I was delighted about their tool that in fact, we intensively used. I still remember talking with them about the importance of data, particularly curated data for embrace the AI or advanced ML models adoption. Maybe it can be seen as a bit old fashioned but the saying “garbage in - garbage out” screams even louder today, stochastic software (LLM based I mean) is all around, and what is more worrisome is that few ones are controlling properly what it actually does. In my view most software engineers are “wired” to put on the table a solution given a set of requirements (I used to be one of them many years ago), that it’s ok, if software behavior is deterministic, which is no longer the case in the agentic-fashion one.
In any case, in the real world dataset sourcing is a hard chore, you need to collect or build it as an artisan. In fact the roles most suited for that are not used to that (or do not have the tools). These difficulties are pushing the pervasive adoption of synthetic data, especially the big tech are incorporating this feature as a key element in their portfolio. What’s more it is expected an exponential growth from the 330 million USD back in 2023 to the astonishing 2.1 billion by 2028 No so big as the ones mentioned above, but its worth it a look at it, this morning I saw a project from these guys called sheets, it is able to generate dataset on demand based on a general prompt “give a dataset of fraud cases for an ecommerce’s customer care chatbot”, or enlarging an input csv file.
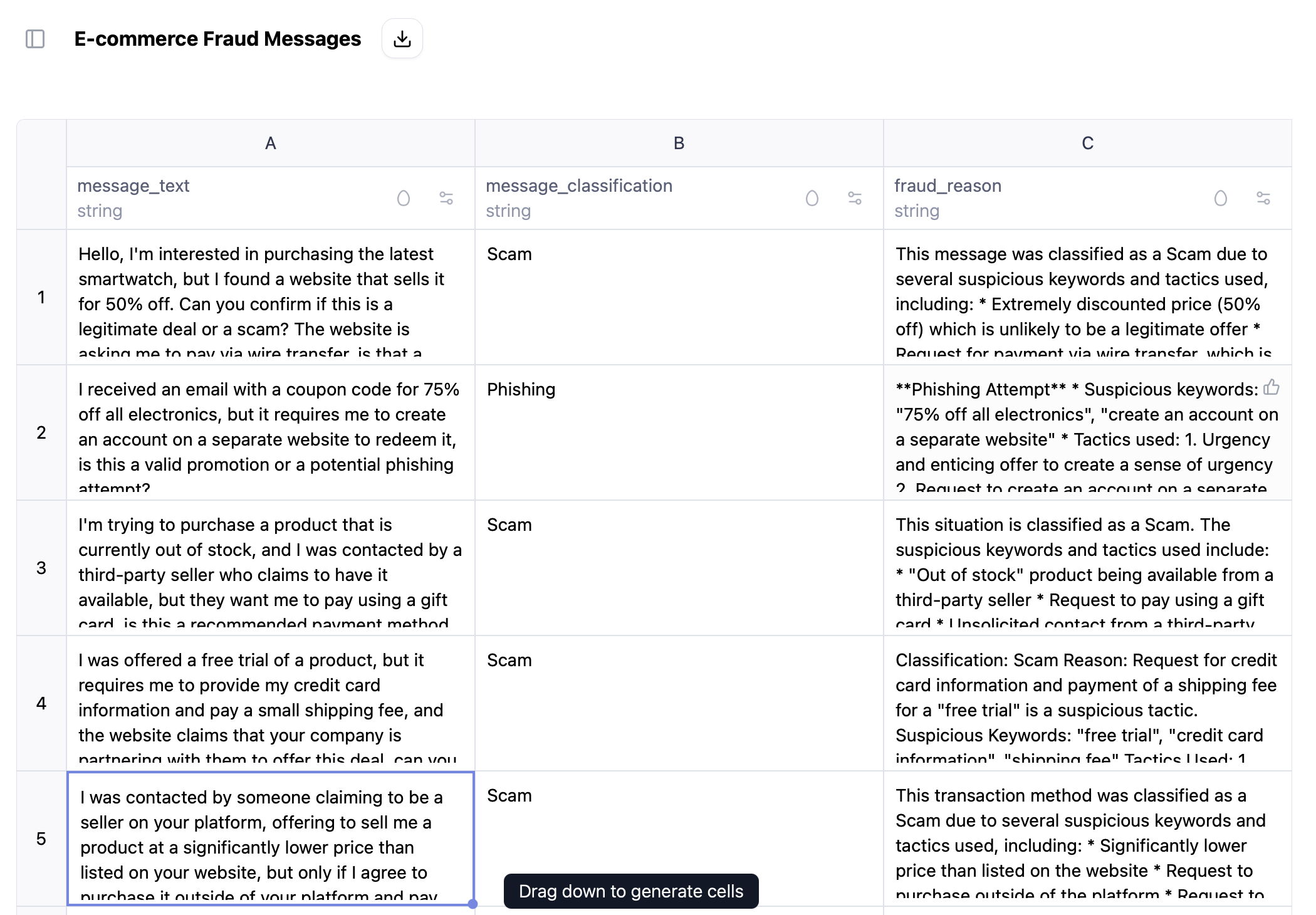 Dataset generated using sheets for “fraud cases for an ecommerce’s customer care chatbot”
Dataset generated using sheets for “fraud cases for an ecommerce’s customer care chatbot”
This is nice not only for agentic applications, but also for “traditional” machine learning models construction or prototyping. I guess it can come in handy to find “uncovered” cases, or for the definition of labeling manuals.
But, what discipline is this?, it’s the automation of dataset construction and curation called “dataset engineering”, that is complementary to other software engineering siblings:
- traditional software engineering
- machine learning engineering
- data engineering
- dataset engineering
dataset versus data engineering
Despite the similarity in name, they are very different disciplines. Dataset regards the automated or AI assisted build and curation of data, while data engineering is the design of the pipelines where data will flow in a production environment.
Some notes about dataset engineering
Dataset engineering is an emerging discipline that focuses on the systematic creation, management, and refinement of datasets tailored for training large language models (LLMs). Unlike traditional workflows that simply amass vast amounts of raw text, dataset engineering emphasizes quality, relevance, and alignment with specific downstream tasks. This data-centric paradigm has gained traction as practitioners recognize that model performance often hinges more on the underlying data than on incremental model architecture tweaks. Early efforts, such as EleutherAI’s “The Pile,” illustrate how constructing a diverse, multi-source corpus can improve LLM generalization by combining web crawls with books, academic papers, and code repositories .
Creating new datasets for LLMs typically involves three stages: sourcing, transformation, and augmentation. Sourcing may draw on public-domain texts, domain-specific archives, or synthetically generated examples. For instance, the Dolma corpus aggregates three trillion English tokens from a blend of web content, scientific literature, and social media, with extensive documentation to support reproducibility. Transformation pipelines then normalize formats (e.g., JSONL), remove duplicates, and redact sensitive information. Tutorials like NVIDIA’s NeMo Curator showcase how custom document builders and filtering heuristics can automate these steps when working with smaller benchmarks such as TinyStories.
Curation is increasingly being delegated to intelligent agents powered by LLMs themselves. The DCA-Bench benchmark evaluates how well such agents detect subtle quality issues—misannotations, incomplete metadata, or ethical red flags—in real-world datasets drawn from multiple platforms. By integrating evaluator agents that mirror human judgments, researchers can automate iterative feedback loops, flagging problematic samples and suggesting corrective actions. This agent-driven approach promises to scale quality assurance far beyond what manual review could achieve.
Looking ahead, dataset engineering will be central to responsible and efficient LLM development. Open repositories (e.g., the “LLM Engineer’s Handbook” on GitHub) curate best practices and tools, stressing accuracy, diversity, and complexity as core design principles . As tooling matures, we can expect richer metadata schemas, dynamic data augmentation, and tighter alignment between agent-based curation and downstream evaluation metrics—ushering in a new era where data craftsmanship underpins the next generation of language AI.