In today’s data-driven world, the term Modern Data Platform (often used interchangeably with Modern Data Stack, MDS) refers to the technology ecosystem and architecture that an organization uses to collect, store, process, and analyze data at scale. In simple terms, a data platform is the set of components through which data flows (storage, processing, analytics, etc.), while the data stack is the set of tools that implement those components . The modern approach emphasizes flexibility, scalability, and accessibility, enabling teams to derive insights faster and make data-informed decisions.
 A modern data stack is like a lot of sandwiches with layers and layers of ingredients. Image generated with gpt4o
A modern data stack is like a lot of sandwiches with layers and layers of ingredients. Image generated with gpt4o
What makes the modern data platform “modern”? A few defining characteristics stand out. First, it is typically cloud-first – leveraging cloud infrastructure for elastic scalability and lower maintenance overhead . Second, it centers around a cloud data warehouse or data lake as a single source of truth for analytics . Instead of monolithic all-in-one systems, an MDS is often a collection of specialized, modular tools connected into end-to-end pipelines . For example, an organization’s stack might include a pipeline tool for ingestion, a separate engine for transformations, a data warehouse for storage, a BI tool for visualization, etc. Each tool focuses on one aspect of data management, which in theory allows teams to “mix and match” best-of-breed solutions for each function.
The rise of the modern data platform is tied to its business importance. Organizations today accumulate massive amounts of data – from user clickstreams to transaction records – and need to glean actionable insights in order to stay competitive. A well-designed data platform enables faster, more reliable analytics and machine learning: companies can integrate diverse data sources, transform raw data into clean “single sources of truth,” and deliver insights via dashboards or models. In fact, building an enterprise data platform has moved from a luxury to a necessity; many companies now differentiate themselves based on how effectively they can harness data for better customer experiences, higher revenues, or even training AI models . Modern data platforms also democratize data access across organizations. By abstracting away technical complexity, they allow analysts, product managers, and even non-technical users to leverage data (often through familiar interfaces like SQL or low-code tools) without needing deep engineering expertise . In short, the modern data platform matters because it is the engine that turns raw data into business value – and it does so in a way that is faster, more scalable, and more user-friendly than traditional data architectures.
Origins: From Traditional Warehouses to the Modern Data Stack
To understand why the modern data platform emerged, it helps to look at how data architectures have evolved. Decades ago, the standard was the enterprise data warehouse (EDW). Companies would extract data from operational systems, transform it according to a strict schema (applying business rules, cleaning, and integration), and load it into a central relational warehouse – a paradigm known as ETL (Extract, Transform, Load). Classic data warehouses (often on-premises) had “schema-on-write” rigidity: the schema had to be defined upfront and data had to fit it, which made handling change slow. Scaling these systems was costly, because one could usually only scale vertically (buying bigger, more powerful hardware) to handle more data or users . This meant large upfront investments and limited agility; only big enterprises with deep pockets could afford the infrastructure and specialized ETL engineers required to make it work.
The mid-2000s brought the Big Data revolution, introducing new paradigms to cope with exploding data volumes and variety. Frameworks like Hadoop (and its MapReduce programming model) enabled organizations to horizontally scale on clusters of cheap commodity servers . Suddenly, you could store and process huge datasets (think petabytes) by spreading them across many nodes. This gave birth to the concept of the data lake – a large storage repository holding raw data in its native format, usually on a distributed filesystem. Data lakes (often built on Hadoop or cloud object storage) took a “schema-on-read” approach: you could dump data in first and decide how to structure/use it later. This was very flexible, but came with a downside – the raw data was often messy, and reading it required heavy-lifting in code. Early Hadoop-based analytics demanded specialized skills in Java/Scala or complex frameworks, which made the user experience “clunky” and limited broad adoption . Only the biggest tech firms and research outfits could really capitalize on Hadoop’s potential, while smaller companies struggled with its complexity.
The next inflection point was the rise of cloud computing and cloud data warehouses. In 2012, Amazon introduced Redshift, the first fully managed cloud data warehouse . Redshift (and successors like Google BigQuery and Snowflake) combined the scalability of the big-data era with the user-friendly query interface of the old SQL warehouses. This was a game changer: it allowed storing massive volumes of data on distributed infrastructure yet querying it with plain SQL, lowering the barrier for analysis dramatically . At the same time, cloud data warehouses separated storage and compute, meaning you could scale them independently and only pay for what you use, which improved cost efficiency and elasticity. In parallel, organizations were adopting SaaS applications and microservices, leading to many disparate data sources (CRM systems, web analytics, NoSQL databases, etc.). Loading all that semi-structured data into a traditional warehouse was painful. The new cloud warehouses handled JSON, nested data, and semi-structured formats better, and they could ingest data continuously. This ushered in an ELT (Extract, Load, Transform) approach – data is first extracted and loaded in raw form into a warehouse or lake, and then transformed in-place (inside the warehouse or with cloud processing engines) to create the cleaned, usable data models . ELT leverages the power of modern warehouses/lakes to do transformations on demand, rather than requiring strict processing before loading. This shift significantly streamlined data pipelines.
By the late 2010s, a “Modern Data Stack” began to coalesce as companies assembled collections of cloud-based tools to handle each step of the data life cycle. Several trends fed this movement :
-
Democratization of Technology: Public cloud made enterprise-grade infrastructure accessible to even small companies, eliminating huge upfront costs . Open-source and SaaS tools proliferated, often with easy adoption and pay-as-you-go pricing, so teams could experiment and adopt tools quickly without large capital expense .
-
Need for Better Tooling: While cloud warehouses solved storage and query scalability, other challenges remained – e.g. data transformation, data quality, pipeline reliability, governance. Fast-growing businesses were frustrated that data still wasn’t easily yielding insights despite their infrastructure investments. This spurred innovation in new tools: for instance, companies like Fivetran emerged for automated data ingestion, dbt for SQL-based transformation, Airflow for orchestration, etc. Venture capital poured into this space, and a wave of startups and open-source projects appeared to tackle every niche of the data workflow .
-
Big Data Meets SQL: There was a desire to combine the scale of data lakes with the ease-of-use of data warehouses. This convergence gave rise to the data lakehouse architecture – essentially bridging data lakes and warehouses. Early implementations (like Apache Hive) put SQL on Hadoop; more recently, technologies like Apache Spark and table formats like Delta, Apache Iceberg, and Apache Hudi (see A short overview on Lakehouse open formats added data management features (ACID transactions, schema evolution) on data lakes . The lakehouse concept aims to offer the reliability and performance of a warehouse directly on a data lake. We’ll touch more on this later.
The modern data platform emerged from this architecture shift: from rigid, on-premise data warehouses and batch ETL processes, to flexible cloud-based ecosystems that embrace both data lakes and warehouses, handle structured and unstructured data, and support both batch and real-time processing. This evolution has been driven by the need to handle greater scale, speed, and diversity of data, while also making data more accessible across organizations.
Core Components and Architecture of a Modern Data Platform
This stack of technologies is often described in terms of layers or components that correspond to the stages of the data pipeline, from raw data generation to business value. While every company’s stack may vary, the fundamental building blocks are quite consistent . Let’s break down the typical components and how modern platforms organize data and workflows.
Key Components (Layers) of the Stack: At a high level, an MDS includes components for data ingestion, storage, processing/transformation, analytics/BI, and often supporting layers for orchestration, governance, and observability . One way to enumerate the must-haves:
-
Data Ingestion: Tools or services to collect data from various sources and load it into the platform. This could be batch ingestion (e.g., scheduled ETL jobs pulling from databases or APIs) or real-time ingestion (streaming data via event streams). Modern stacks often use specialized connectors (e.g. Fivetran, Airbyte) for easy ingestion of SaaS data, or streaming platforms like Kafka for event data.
-
Data Storage & Processing: A scalable data warehouse or data lake that serves as the central repository. Examples include Snowflake, BigQuery, Amazon Redshift (warehouses), or data lakes on S3/HDFS with frameworks like Databricks (Spark) or Synapse. Often a combination is used (a lake for raw data, a warehouse for refined data). Cloud object storage + SQL query engines can also act as the warehouse/lakehouse. This layer handles storing raw and processed data, and provides the compute engine to query or process it.
-
Data Transformation & Modeling: Once data is stored, it typically needs to be cleaned, joined, and reshaped into usable forms (e.g., building a dimensional model or feature tables for ML). Transformation can be done by writing SQL in tools like dbt (which runs SQL in the warehouse to create new tables) or via dataflow/Spark jobs in code. Modeling often implements business logic to create “one version of truth” metrics and dimensions. This layer is crucial for data quality and consistency.
-
Consumption & Analytics: This is how data gets to end users – often through Business Intelligence (BI) tools (like Tableau, Looker, Power BI) for dashboards and reporting, or via data science notebooks and ML tools for advanced analytics. Modern data platforms treat these consumers as first-class: data might be served in a metrics layer (semantic layer) to ensure consistent calculations in BI, or via APIs to feed applications.
-
Orchestration: With many steps in the pipeline, you need workflow orchestration (e.g., Apache Airflow, Prefect, Dagster) to schedule and monitor jobs – ensuring, for example, that ingestion runs before transformation, which runs before a daily report is refreshed. Orchestrators help manage dependencies and automate the end-to-end data flow.
-
Data Quality & Observability: As pipelines grow, monitoring data health is critical. Modern stacks often include data observability tools (e.g., Monte Carlo, Great Expectations) that detect anomalies, broken data, or pipeline failures. This ensures trust in the data by alerting teams to issues like missing records or schema changes. Data governance tools and catalogs (e.g., Atlan, Collibra) also come into play here, helping track metadata, lineage, and access control for compliance and security.
All these components together form the modern data platform. In earlier eras, one monolithic system (like a single data warehouse appliance) might have tried to do all of this. In the modern paradigm, these functions are often implemented by distinct, specialized tools that the data engineering team stitches together. This modularity has benefits – you can choose best-in-class tools for each function – but also introduces complexity (as we’ll discuss in the criticisms section). Many modern data platforms are thus depicted as stacks of tools, one for each layer, connected via data flows and APIs . For example, your stack might have: data ingestion by Fivetran → land raw data into Snowflake (storage) → transformations managed by dbt in Snowflake → orchestration by Airflow to schedule dbt and other tasks → BI in Looker → monitoring by an observability tool.
Organizing Data: Curation Layers (Bronze, Silver, Gold)
A hallmark of modern data platform design is how data is organized into tiers of refinement, often referred to as curation layers. Rather than dumping everything into one place, teams impose a logical structure that tracks the data’s journey from raw to refined. A well-known design pattern for this is the Medallion Architecture, which uses Bronze, Silver, Gold layers to organize a data lake or lakehouse .
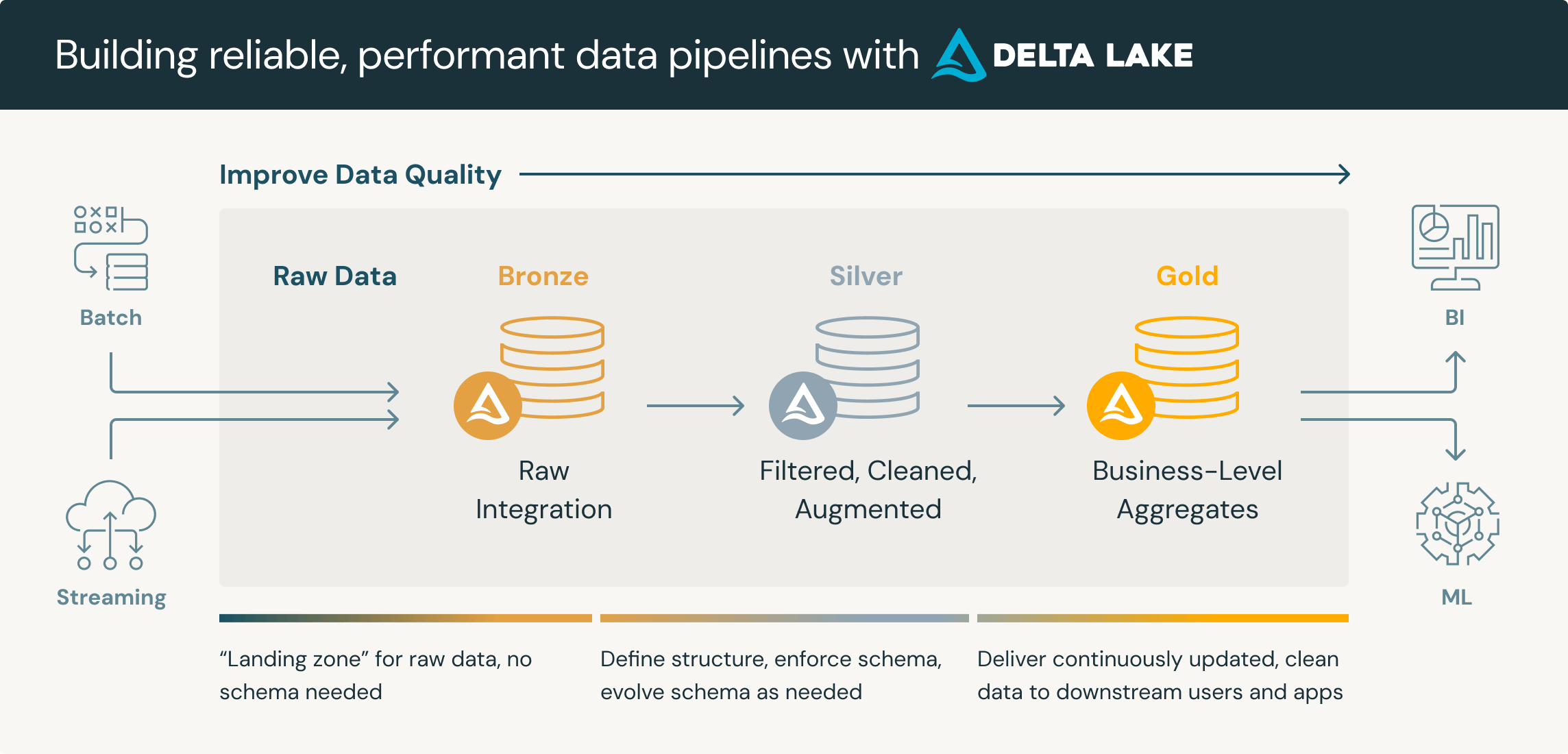 Medallion architecture composed by 3 layers: bronze, silver and gold. Source: Databricks
Medallion architecture composed by 3 layers: bronze, silver and gold. Source: Databricks
-
Bronze Layer (Raw Data): This is the landing zone for raw data – an immutable, low-touch copy of data from source systems, stored in its original detail. The raw/bronze layer acts as the “data swamp” where everything is retained (often for compliance or reprocessing needs) and can be reprocessed if needed. In an ELT approach, this is where data lands before significant transformation . The raw data might be stored as files in a data lake (e.g., JSON logs, CSV extracts) or as initial tables in a warehouse, and typically only lightweight schema is applied (e.g., basic types or partitions). The key idea is no information is lost – even if it’s messy – to preserve full context.
-
Silver Layer (Cleansed & Conformed Data): In this layer, data from bronze is validated, cleaned, and conformed to a known schema or set of standards . Here, obvious errors are fixed, types standardized, and different sources integrated into a coherent form. For example, you might parse JSON fields into columns, handle missing values, or join reference data (like attaching customer IDs to transactions). The silver layer is often where schema-on-read meets schema-on-write: even if the raw layer was schema-on-read, by the silver stage you enforce schemas and data quality rules so that downstream processes have reliable inputs . Think of silver as the single source of truth for core entities – e.g., a clean table of customers, a refined log of all events, etc. This layer is used by data engineers and scientists for exploration and serves as the foundation for more polished data products.
-
Gold Layer (Curated Data Products): The gold layer contains aggregated, highly refined data ready for business use. These are the tables or views that feed dashboards, reports, or ML models – essentially data products for specific needs. Gold data is typically business-friendly: e.g., a table of KPIs by region, a dataset of customer lifetime value scores, or any table that answers a specific analytics question. Data here is often denormalized and optimized for read performance (analytics queries), and sensitive or irrelevant details may be filtered out. Gold tables often have governance applied (who can see what) and are the ones most “trusted” by end users. By the time data reaches gold, it has passed through quality checks in prior layers and is known to be reliable and up-to-date.
This layered approach (Bronze/Silver/Gold) ensures a pipeline of incremental improvements to data quality as data flows through the platform . Each layer has a distinct purpose and audience: raw for data engineers and forensic analysis, cleansed for analytics development, curated for broad consumption . It also provides modularity – if an upstream process fails or a source system changes, it might only affect the bronze layer, and your silver/gold data can be insulated or recovered from the raw data once issues are fixed. Modern cloud data platforms (like Databricks with Delta Lake, or Snowflake) often explicitly encourage this pattern, with features like time travel and ACID transactions to manage these transformations safely .
The medallion architecture is just one example; some organizations have more layers (e.g., a staging or landing zone before bronze, or multiple presentation layers after gold for different user groups ). Others may use different naming (like bronze = “raw”, silver = “integrated” data, gold = “trusted” data, etc.). But the core idea remains: structure your data pipeline in layers that progressively refine data. This pattern aligns well with ELT workflows – you Extract and Load to bronze, then Transform through silver to gold in successive steps . It stands in contrast to the old ETL-in-one-shot approach, offering more flexibility (you can re-run transformations easily or adjust logic without re-extracting from sources) .
Processing Workflows: Batch, Micro-Batch, and Streaming
Another key aspect of modern data platforms is how they handle data processing workflows, particularly the frequency and latency of data updates. Traditionally, data was processed in batches – e.g., a nightly job that aggregates the day’s transactions. Modern requirements have pushed platforms to support ever more real-time data processing. We can distinguish three main approaches:
-
Batch Processing: This is the classic approach: accumulate a large batch of data over a period (say, hourly or daily) and then process it in one go. Batch processing tends to introduce higher latency (data is only fresh up to the last batch run), but it allows complex computations over entire datasets and is often simpler to implement. Many analytics use cases are still well-served by batch updates – for example, generating a daily sales report at 8 AM from the previous day’s data is fine if decisions are made daily. You would choose batch when ultra-fresh data isn’t critical, when you need to join or sort very large datasets in one operation, or when your data sources naturally come in batches (e.g., a daily CSV export) . Batch frameworks include classic Hadoop MapReduce, or modern cloud workflows using SQL or Spark on scheduled intervals. In an MDS, even if you have real-time components, some layer (like the gold layer for financial reporting) might still be batch, trading speed for completeness and thorough checks.
-
Stream Processing: Streaming (or real-time) processing means data is processed continuously as it arrives, often within seconds or milliseconds . Instead of waiting for a whole day’s data, a streaming pipeline might update metrics every few seconds or trigger alerts as events happen. This is crucial for use cases like fraud detection, real-time personalization, IoT sensor monitoring, or immediate operational dashboards . Stream processing systems deal with unbounded data (never-ending streams of events) and emphasize low latency. They typically maintain minimal state (or only small windows of data) to process events on the fly. Technologies enabling streaming include Apache Kafka for event transport, and stream processors like Apache Flink, Apache Kafka Streams, or Spark Structured Streaming. Many of these can handle high-velocity data and do windowed aggregations, joins, etc., on streaming data. In practice, true pure streaming (event-at-a-time processing) is used when sub-second or a few seconds latency is a hard requirement and the logic can be done incrementally . For instance, updating a real-time dashboard of website activity or making an instant recommendation to a user.
-
Micro-Batch Processing: Micro-batching is somewhat a middle ground – it involves processing small batches of data at very frequent intervals (say every minute or every few seconds), rather than one-record-at-a-time continuous streaming. The distinction between micro-batch and streaming can be subtle; in fact, some systems marketed as streaming are internally micro-batching for efficiency. A prime example is Spark Streaming, which by design processes data in tiny time-sliced batches (e.g., every 1 second) – this gives near-real-time results with a slight delay but can achieve higher throughput by amortizing overheads . Micro-batch is useful when you need fresh data fast (faster than classic batch), but an extra few seconds of latency is acceptable and it significantly simplifies the system or improves efficiency. Use cases could be things like updating a dashboard every minute or monitoring user behavior on a website with minute-level granularity . Many “streaming” data integration tools (like some cloud ETL services) actually employ micro-batch: for example, they might fetch new records from an API every few minutes and append them to the data store, which feels real-time for many business needs.
Modern data platforms often incorporate all three approaches in different parts of the system, depending on use case. For instance, raw event collection might be streaming (ingesting user events in real time into a message queue), intermediate aggregation could be micro-batched (rolling up events every minute to reduce noise), and heavy-duty analytics might be batch (calculating yesterday’s totals). Choosing between batch, micro-batch, and streaming involves a trade-off among latency, complexity, and completeness . Generally, real-time pipelines are more complex to maintain (and can be harder to guarantee correctness, since out-of-order or late data becomes an issue). So it’s wise not to over-engineer for real-time if the business doesn’t need it. Many organizations start with daily or hourly batch jobs and only move to streaming for specific cases that demand it.
One architectural note from the past: the tension between batch and streaming led to the Lambda Architecture (an early 2010s concept) where you maintain two parallel pipelines – a batch pipeline for accuracy and a streaming pipeline for speed, merging results. Lambda architecture provides both correct (but slow) and fast (but approximate) views. However, maintaining two code paths is cumbersome. Newer systems aim for a unified pipeline (sometimes called Kappa architecture or simply modern stream processing), where the same code can handle both historical and real-time data. Tools like Spark Structured Streaming or Flink with stateful streaming try to achieve this unification. The modern data platform ideally should allow a seamless spectrum from batch to real-time as needed.
Data Mesh and Data Fabric: Evolving Paradigms in Data Architecture
Beyond the technology components, modern data platform discussions often intersect with higher-level architectural paradigms like Data Mesh and Data Fabric. These concepts address how data is organized and managed across an enterprise, and they can influence how you design your data platform (or vice versa).
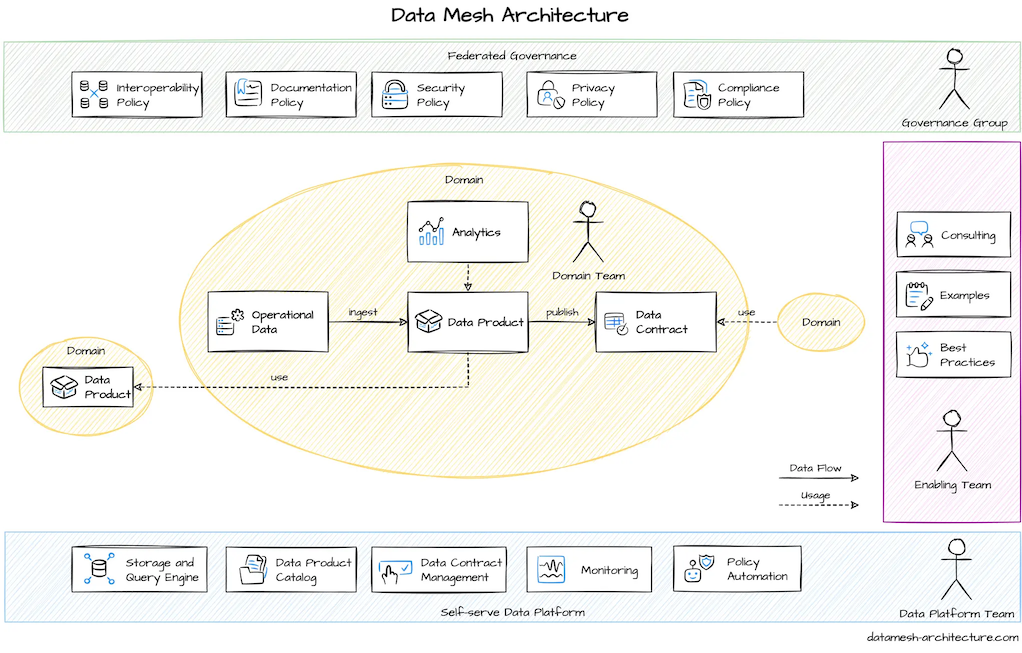 Data Mesh design princiles Source: Datamesh Architecture
Data Mesh design princiles Source: Datamesh Architecture
-
Data Mesh – Introduced by Zhamak Dehghani in 2019, data mesh is not a technology stack per se but rather an architectural and organizational approach. It proposes a move away from centralized data teams and monolithic data lakes/warehouses towards a decentralized, domain-driven model . In a data mesh, each business domain (for example, Marketing, Sales, Finance, etc.) owns its data as a product – meaning they are responsible for producing, curating, and serving their data to others. The idea is to treat data like a product with clear owners, SLAs, and documentation, rather than an IT byproduct. Domains publish data in a way that other teams can easily discover and use it (often through a central data catalog or “data marketplace”). Data mesh addresses organizational scaling problems: as companies grow, a single central data team becomes a bottleneck for all analytics. Mesh tries to scale out by empowering domain-aligned teams (who have the business context) to manage data, while still following common governance standards. Key principles of data mesh include domain ownership, data as a product, self-serve data platform (meaning the central team provides infrastructure as a platform that domains use), and federated governance (i.e., a balance between central guardrails and local control) .
How does this relate to a modern data platform? Essentially, a data mesh can be implemented using a modern data platform. The technology stack might look similar (ingestion, lakes/warehouses, etc.), but instead of one centralized pipeline, you’d have multiple pipelines run by different domain teams, all feeding into a shared platform or interoperable environment. For example, the Sales team might maintain their own ingestion and transformation pipelines for sales data, and the Marketing team does the same for marketing data, but both publish clean data sets to a common catalog where anyone can find them. The modern data stack has made data infrastructure easier to self-serve (with cloud and SaaS tools), which in turn enables the data mesh concept – domain teams can actually run their own pipelines without having to build everything from scratch. Many organizations are experimenting with data mesh to improve agility and align data closer with business context, though it requires cultural shifts and maturity in data governance.
-
Data Fabric – This term, popularized by analysts like Gartner, refers to an architectural approach or set of technologies that aim to provide a unified, intelligent data management layer across an enterprise’s distributed data assets. A data fabric is often described as an automated system that integrates data and metadata across multiple repositories and environments, making it feel like one cohesive framework . Key features often include metadata-driven pipelines, use of AI/ML to automate data integration tasks, and a focus on data discovery, governance, and accessibility. In simpler terms, a data fabric is a bit like an overlay that connects all your databases, data lakes, warehouses, and streams, and uses metadata (information about the data) plus automation to do things like discover relationships, enforce data quality, and route queries to the right place.
A data fabric is more technology-centric (where data mesh is people/process-centric) . For example, a data fabric solution might automatically crawl all your data sources, index their schemas in a central catalog, apply standardized transformations, and let users query data without worrying where it’s stored or how it’s formatted – the fabric handles the complexity under the hood. It often relies on knowledge graphs, metadata catalogs, and AI to achieve this smart integration . Some vendors offer “data fabric” products that promise to connect data across on-prem and cloud, SQL and NoSQL, etc., presenting a unified view.
Think of data fabric as an architectural vision to simplify data access in a complex, heterogeneous environment. It complements the modern data platform by addressing the sprawl of data – whereas a modern data stack often consolidates data into a lake or warehouse, in reality large enterprises still have many siloed systems. A data fabric seeks to weave those silos together. For instance, if you have customer data in a CRM, more data in a cloud warehouse, and some in a data lake, a data fabric would help ensure that no matter where a user or application looks for “customer” data, they get a consistent, governed view. According to Gartner, a data fabric is an “integrated layer (fabric) of data and connecting processes” that spans across locations, providing a unified data environment .
Mesh vs Fabric: These two concepts are not mutually exclusive – in fact, some experts suggest they can be used together . The simplest distinction is: data mesh is about decentralizing ownership and operations (people and process), while data fabric is about centralizing connectivity and metadata (technology) . A data mesh might leverage a data fabric’s technology to connect domain data products under the hood. Conversely, you could implement a data fabric in a centralized org or a decentralized one. Both aim to deal with the complexity of modern data environments: mesh by federating responsibility, and fabric by abstracting complexity through a smart architecture. For a CTO or engineer, it’s important to recognize that adopting a modern data platform (the tools) can be done independently of these paradigms – but aligning your platform with either approach could yield different benefits. For example, if you go the data mesh route, you’ll invest in tooling that supports self-service by domains (like user-friendly transformation tools, domain-oriented catalogs, etc.) and you’ll design your data platform to allow independent deployments per domain. If you lean towards data fabric, you might invest in master data management, universal query engines, or active metadata systems to automate integration.
The bottom line is that both, data mesh and data fabric, are paradigms that influence how you structure and govern your modern data platform. They are not opposed, they are rather than two different standpoints of the same question. Mesh is a sociotechnical approach distributing data development across teams, and fabric is an architectural approach to smartly integrate and deliver data in a unified way. Both arise from the need to handle increasing scale and complexity in enterprise data landscapes, and a modern data platform can be seen as the foundation that can enable either (or both) approaches.
Hype vs. Reality: Criticisms of the Modern Data Stack
With all the buzz around the modern data stack, it’s worth asking: is this just hype and over-engineering? In recent years, many practitioners have started voicing criticism of the overly complex ecosystems that have emerged. While the modern data platform brought undeniable improvements, it also introduced challenges:
1. Tool Sprawl and Integration Complexity: Perhaps the most common critique is that the modern data stack became too modular for its own good. A typical stack might include 5-10 different specialized tools, each excellent on its own, but the data team spends enormous effort gluing them together and maintaining integrations. As one observer quipped, “Suddenly, you weren’t doing data unless you had: a cloud warehouse, a pipeline tool, a transformation layer, an orchestrator, a BI tool, a reverse ETL, data quality, metadata, and a side of observability, lineage, CI, semantic layers… Each tool makes sense on paper. But in reality? You spend more time wiring things up than shipping value.” . This resonates with many engineers who find themselves building and debugging the connectors between systems rather than focusing on delivering insights. Every additional tool is another point of failure: if one component in the pipeline breaks, it can cause cascading failures down the line . Managing dependencies and versions across tools, dealing with API changes or integration bugs – all of this adds operational burden.
2. Over-Modularity and “Frankenstack” Costs: The sheer number of tools and vendors in the data ecosystem led to what Benn Stancil called over-modularity – breaking the stack into too many pieces . Data teams may end up maintaining a “house of cards” where the complexity is high relative to the actual business value delivered. Small companies especially might find that the classic modern stack is overkill; they don’t have the scale to justify such complexity, and a simpler solution might suffice. Additionally, costs can balloon: each SaaS tool has its own pricing (often consumption-based), and the cumulative cost of running a full suite of tools can surprise teams. It’s not uncommon to hear complaints about the Snowflake bill, the ETL tool bill, the BI tool bill, etc., adding up to significant expense – sometimes for functionality that overlaps or that could be achieved with fewer moving parts. In 2021-2022 the industry saw a hype peak for the modern data stack, but by 2023 a bit of a hangover: companies started scrutinizing if all those tools were truly necessary . The time-to-value which the MDS promised can get lost when engineers are bogged down managing infrastructure and fighting integration fires.
3. Talent and Learning Curve: With a fragmented stack, the skill set needed by data engineers broadened. Instead of being proficient in one integrated platform, engineers must learn the ins and outs of multiple systems (and how they interact). Onboarding new team members can be slower – they must absorb the nuances of your particular combination of tools. Each tool might have its own DSL or configuration language (think of learning SQL vs. Python vs. YAML config for an orchestrator vs. a custom formula language in a BI tool). There’s also a lack of global observability – when something goes wrong, tracing the root cause across tool boundaries (is it a data issue from upstream source? a bug in the transform logic? a pipeline scheduling delay? an API limit in the ingestion tool?) can be non-trivial . It requires holistic knowledge that is hard to maintain when responsibilities are siloed by tool expertise.
4. Is More Always Better? Detractors also point out a tendency toward tool-heavy solutions when sometimes a leaner approach could work. Not every company needs real-time streaming + a lakehouse + a warehouse + 5 different data science platforms. There’s a critique that the MDS vendors (and the media/blogs around them) encouraged a “bigger stack = better” mentality, which isn’t always aligned with business needs. Some data engineers now advocate for a return to simplicity: using fewer tools, sticking to well-known technologies, and focusing on good data modeling and quality over chasing the newest shiny tool. As one article bluntly stated, “The modern data stack is overrated. What works? Fewer tools, clear ownership, and systems your team actually understands.” .
5. Security and Governance Gaps: Another challenge is that when you have many tools, governance can fall through the cracks. Who is ensuring that your data access policies are consistently applied across the ingestion tool, the raw storage, the warehouse, and the BI extracts? It’s tricky. Sensitive data might be duplicated across multiple systems (e.g., a PII-containing dataset lands in the lake, then moves to the warehouse, then appears in a spreadsheet) and controlling that with a cohesive policy is hard if your stack isn’t tightly integrated. Similarly, lineage (knowing how data moves from source to report) becomes hard to trace when each transformation is happening in a different layer with different logging. While new metadata tools have arisen to tackle this, it’s still a work in progress for many.
6. The Hype Cycle – Entering the Trough: The modern data stack had been a hot buzzword, but some now argue it’s entering a more mature phase where hype dies down and realism sets in. Tristan Handy (CEO of dbt Labs, a key figure in the MDS space) wrote an essay in early 2024 essentially calling the modern data stack a “useful idea whose time had passed”, suggesting that the concept had peaked in utility and we needed to move on. His perspective, echoed by others, is that while the MDS solved a lot of yesterday’s problems (making data warehousing accessible, etc.), it created new ones in terms of complexity and total cost of ownership . We might be at a point where a next evolution is due.
In fairness, many in the industry still strongly believe in the modern data platform approach – but with a dose of pragmatism. Few argue that we should return to the old days of single monolithic systems; rather, the criticism is about finding the right balance. As Itamar Ben Hemo of Rivery reflected, “the modern data stack did its job: it lowered the barrier of entry to working with data and made data easily accessible… But now, the overwhelming amount of tools is making it challenging for data teams to deliver value quickly and cost-effectively” . The key is to avoid getting caught in an endless cycle of adding tools for every micro-problem, and instead focus on the cohesive platform outcome – delivering fast, clean, reliable data to the business .
Towards Simpler, Integrated Architectures: Lakehouse and “LakeDB”
Given the challenges above, there’s a growing interest in simplifying the data platform architecture. This doesn’t mean going back to legacy systems, but rather rethinking how the benefits of the modern stack can be delivered with fewer moving parts. Two related trends illustrate this: the rise of the Lakehouse architecture, and new visions like LakeDB that push integration even further.
 Image generated with gpt4o
Image generated with gpt4o
Lakehouse – Unifying Data Warehouses and Lakes: The lakehouse concept, championed by companies like Databricks, is essentially an attempt to consolidate the roles of a data lake and a data warehouse into a single platform. In a traditional modern stack, you might have a data lake (for raw, large-scale storage, often on HDFS/S3) and a separate data warehouse (for fast SQL analytics on refined data). This can lead to data duplication and maintenance overhead (ETLs to sync lake and warehouse). A lakehouse seeks to provide one platform for both storage and analytics, typically built on low-cost cloud storage with an added layer that provides warehouse-like capabilities on top. Technologies like Apache Iceberg, Apache Hudi, and Delta Lake are core to this, as they bring database-like features (transactions, schema management, indexing) to files in a data lake . With these, you can get reliable, ACID-compliant tables on data lake storage. The promise is that you no longer need to maintain two copies of your data (one in a lake, one in a warehouse); the lakehouse is your single repository, open for big data processing and SQL analytics alike.
In practical terms, a lakehouse might mean using Databricks or another Spark-based system with Delta Lake as your primary data platform, instead of say a separate Hadoop + Snowflake. Or using Snowflake’s recent capabilities to handle semi-structured data and even enable data science, thereby reducing the need for a separate lake. The medallion (bronze/silver/gold) architecture fits naturally in a lakehouse model – with all those layers implemented on the lakehouse itself rather than shipping data to different systems.
Consolidation and All-in-One Platforms: Beyond just the lakehouse storage concept, there’s a broader move towards consolidation of tools into platforms. Vendors are expanding their offerings to cover more stages of the pipeline. For example, Snowflake now offers not just a warehouse, but also native ingestion (Snowpipe), data science (Snowpark), and even an application runtime; Databricks is integrating MLFlow, Delta Live Tables for pipeline orchestration, etc. Meanwhile, cloud providers like Microsoft launched Microsoft Fabric (in 2023) as an end-to-end analytics platform that combines data factory (ingestion), a data lake, a warehouse engine, and Power BI into one seamless product. This is telling – it indicates a recognition that enterprises want simpler architectures where possible, rather than cobbling together dozens of niche products. A recent commentary noted that Microsoft entering this space with a unified offering showed that the “modern data stack was never big enough” as a standalone market – big players are moving in to subsume those capabilities into broader platforms. The pendulum might be swinging back from best-of-breed DIY integration toward more bundled solutions.
LakeDB – The Next Evolution: Perhaps the most futuristic idea in this space is the notion of LakeDB, which is essentially a hypothetical next-gen architecture building on the lakehouse concept. The term comes from a description of Google’s internal system “Napa” which inspired some in the community to envision what a fully integrated analytical data management system could look like . LakeDB is imagined as a system that unifies storage, ingestion, metadata management, and query processing in one . In other words, instead of having a separate ingestion service, a separate catalog, a separate query engine, etc., all these functions would be tightly integrated within one system. The goal is to eliminate the cracks that data falls through in a multi-tool stack.
What would this look like? A LakeDB would handle streaming data ingestion with high throughput, manage the data layout and indexing on storage for optimal query performance, maintain rich metadata and transactional consistency, and serve both high-concurrency queries and continuous processing – all in one coordinated system . Google’s Napa (not publicly available, but described in papers) does things like use a log-structured storage for continuous ingest, automatically maintain materialized views for fast queries, and allow configurable trade-offs between freshness and query performance via a concept called Queryable Timestamp . Inspired by that, LakeDB is a vision where the system (rather than the data engineers) handles a lot of the decisions about whether data should be processed in batch or stream, whether a table should use copy-on-write or merge-on-read for updates, which tables should be materialized or indexed, etc., based on user-defined goals (like “I need this dataset updated within 1 minute of new events, and I care more about fresh data than perfect consistency”) .
In a LakeDB world, many of the current separate tools might become unnecessary because their functionality is absorbed into one platform. For example, you wouldn’t need a separate streaming ingestion framework – the LakeDB would natively ingest streams and make them queryable alongside batch data. You wouldn’t need an external scheduler for basic pipelines – the system could manage dependencies of transformations internally (akin to how a database manages views). The appeal is a dramatic reduction in complexity: instead of a patchwork, you have a cohesive “data operating system”.
Now, LakeDB is still largely conceptual; no single product today fully realizes this vision (we have partial steps: Databricks Lakehouse is integrated but not fully one process doing everything; Snowflake is adding pieces but still not handling real streaming ingestion internally, etc.). However, we see the direction: systems converging. For instance, Apache Iceberg + Kafka + Flink could be assembled to approximate some LakeDB ideas, but that’s still multiple systems. Google’s mention of Napa hints that internally some companies are already operating at the next level of integration. The community experts writing about LakeDB hope that the open-source and vendor community will collectively push the current lakehouse tech to evolve in this direction – essentially making the data platform more like a database again, but one built for the big data, real-time era.
One concrete example of moving in this direction is handling streaming and batch in one. Delta Lake’s recent features (Delta Live Tables) attempt unified pipelines that can do both batch and incremental loads under a hood, hiding complexity . Another example is materialized view management: instead of every team writing their own job to pre-aggregate data for speed, an integrated platform could decide what to pre-compute. These ideas reduce the need for separate orchestration and custom code.
Leaner Isn’t Always Simpler: It’s worth noting that an all-in-one platform like LakeDB (or even current lakehouse systems) shifts complexity but doesn’t eliminate it. The complexity moves inside the platform. This can be great (less for your team to maintain), but it also can mean a very complex system under the hood, which might be hard to troubleshoot if something goes wrong internally. Skeptics of the one-platform-to-rule-them-all approach worry about vendor lock-in or lack of flexibility. There’s a bit of irony: we went from monolithic data warehouses → to modular open stacks → and now are discussing integrated platforms again. The key difference is that the new integrated platforms would be built on modern, open standards and hopefully avoid the rigidness of old monoliths by allowing configurability and using open file/table formats, etc. For instance, a future LakeDB could be an open source project that many vendors implement, ensuring users aren’t stuck with one vendor.
In summary, the response to the “modern data stack is too complex” critique is emerging in two forms: (a) consolidation of existing tools into more comprehensive platforms (as seen with big cloud data services and lakehouse offerings), and (b) forward-looking architectural shifts (like LakeDB) aiming to deeply integrate what used to be separate functions. Both point to a “post-modern” data platform era where ease-of-use, manageability, and end-to-end efficiency are in focus, even if that sacrifices some of the “pick any tool” flexibility of the earlier modern stack philosophy.
The Post-Modern Data Platform
What does the future hold for data platforms? It’s a fast-evolving space, but several clear trends are shaping what the next generation might look like – we could term it the post-modern data platform, where lessons from the first modern wave are applied with a dose of pragmatism and new capabilities.
1. AI-Powered Data Management: One unmistakable trend is the infusion of artificial intelligence into data tooling. Managing data pipelines and quality has historically involved a lot of manual effort – writing transformations, monitoring dashboards, tweaking performance. Now, AI and machine learning are being leveraged to automate and streamline these tasks. For example, we see tools using ML to automatically detect data anomalies, suggest transformations, or even generate code. Major platforms are embedding AI to reduce grunt work: Snowflake can use machine learning to automatically optimize how data is stored and to identify/correct certain errors in incoming data; Databricks is adding AI features to tag and organize incoming data automatically; other tools apply NLP to help data discovery (e.g., allowing users to ask in natural language where certain data is) . Generative AI (like GPT-4) is being eyed as a way to enable non-technical users to interact with data using plain English or to assist engineers by suggesting pipeline code. This goes hand-in-hand with the push for productivity: Monte Carlo’s 2025 trends report notes that AI is revolutionizing every layer of data management, from collection to analysis, automating routine tasks like data cleaning and integration . In practice, this means the future data platform might have an “AI copilot” that helps build your pipelines or a smart system that self-tunes and heals (identifying why a dashboard broke and fixing it, for instance). AI won’t replace data engineers, but it will become a powerful assistant, handling much of the heavy lifting and letting humans focus on defining requirements and interpreting results.
2. Real-Time Everywhere: As businesses require more immediate insights, streaming and real-time analytics will become a default expectation rather than a niche feature. The latency of data availability is shrinking – in a few years, a “daily batch” might feel antiquated except for archival reporting. We already see the push towards real-time in areas like customer experience personalization, operational BI, and monitoring. The future platform is likely to blur the line between operational and analytical data systems. Expect event-driven architectures to rise, where data events trigger analyses automatically and insights are fed back into applications on the fly. With IoT and online services, streaming data volumes will grow, and platforms will need to handle high-velocity streams as easily as they handle static tables. The challenge of course is maintaining consistency and correctness in real-time, which is where innovations like stateful stream processing and better watermarking/late data handling will continue. As one 2025 outlook put it, real-time analytics are reshaping business strategies, meaning companies able to leverage up-to-the-second data will outcompete those who wait for weekly reports . The modern data platform of the future might treat batch as just a special case of streaming (rather than vice versa). We can foresee architectures where all data is processed through streaming pipelines, but some outputs accumulate for batch-like views.
3. Unified and Hybrid Platforms: We discussed integration like Lakehouse/LakeDB – that will likely continue. Cloud vendors will push their unified solutions (we might see, for example, deeper integration between data warehouses and message queues, or built-in support for unstructured data alongside structured). But also, hybrid and multi-cloud support will be crucial. Many enterprises are not 100% in one cloud; the data platform of the future might need to seamlessly span on-prem, multiple clouds, and edge environments. Data fabric concepts will play a role here, using metadata to enable data virtualization – so a user doesn’t need to know where data lives. Technologies like query federation and data virtualization might mature to let a single SQL query join data that’s partly in a lake and partly in a warehouse, or partly on Azure and partly on AWS, without the user caring. In addition, there’s interest in modular architectures that can run anywhere (for example, an organization might want an on-premise mini data stack at an edge location due to latency or privacy, but that can sync with the central cloud platform). Containers and Kubernetes-based deployments of data tools are making this easier, and some databases are going distributed across hybrid environments.
4. Data Governance, Privacy, and Security by Design: Future data platforms will likely bake in governance from the ground up. With regulations like GDPR, CCPA, etc., and more awareness of data ethics, platforms need to manage PII and sensitive data automatically. We might see features like automated data lineage tracking (so you always know where data came from), fine-grained access control that’s consistent across the stack (maybe via a universal access layer), and encryption/security features integrated (so using data in analytics doesn’t accidentally expose what shouldn’t be exposed). “Adaptive governance” is a trend where instead of rigid rules that hinder innovation, governance frameworks become more dynamic – applying controls based on context and usage patterns . For instance, an AI might monitor queries and flag if someone is accessing an unusual combination of sensitive fields. Essentially, expect the platform to take on more of the heavy lifting in keeping data compliant and secure, rather than relying on humans to set all the rules manually.
5. Data as a Product and Self-Service Analytics: The concept of data mesh introduced data as a product, and whether or not one adopts mesh wholesale, the mindset is becoming prevalent: treat datasets like products with clear ownership, documentation, quality standards, and life cycles. This means future platforms will provide better productization tools – think one-click publishing of a dataset with an automatic API, documentation site, quality report, etc. Also, self-service analytics will continue to grow, powered by both improved tooling and by things like natural language interfaces. We might see more widespread use of conversational analytics (ask a question in English, get an answer with a chart, with the system figuring out which data to query). The semantic layer is likely to mature, bridging the gap between raw data and business concepts so that tools (or AI assistants) can help any user get to the data they need without misinterpretation. The aim is to remove the data team as a constant intermediary for every analysis – the platform should enable marketing analysts, operations managers, etc., to find and use data confidently on their own (within guardrails).
6. MDS 2.0 – A Balanced Approach: Some analysts talk about “Modern Data Stack 2.0”, which isn’t a single product but an evolved philosophy. It might involve rationalizing the toolchain (fewer tools, but more robust ones), focusing on cost-efficiency, and aligning more closely with software engineering best practices (treating data pipelines as code with proper DevOps processes). There’s an increasing emphasis on data quality engineering and reliability – essentially, learning from software engineering that testing and CI/CD are crucial, the future data platform will include testing frameworks, version control for data and transformations, and observability similar to application performance monitoring. Data contracts (explicit schemas agreed between producers and consumers) may become standard to prevent breakages when source systems change . So the post-modern stack will not be about chasing every new tool, but about robustness, maintainability, and clear SLAs for data.
7. Domain-Specific and Embedded Analytics: Finally, we may see more specialization in data platforms. Instead of one-size-fits-all, platforms might tailor to specific industries or use cases. For instance, real-time IoT platforms optimized for time-series data, or retail analytics platforms that come with pre-built models and connectors for common retail systems. Also, analytics and data capabilities might increasingly be embedded in operational systems. The line between data platform and application platform could blur – e.g., an ERP or CRM might have native analytical databases built-in, or an AI model might be directly integrated into databases (some databases are now adding vector search for AI, etc.). This means the data platform of the future might not always be a separate thing the way a Snowflake or Databricks is today; it could be under the hood of various software as a transparent layer.
In essence, the post-modern data platform likely brings together the best of both worlds: the scalability and innovation of the modern data stack, tempered by a drive for simplicity, integration, and intelligent automation. The winners in this space will be solutions that can deliver powerful capabilities (AI, real-time, unlimited scale) but package them in a user-friendly, unified experience that doesn’t require a massive team to maintain. We are already seeing steps in this direction with new products and features announced each year. The evolution is continuous – as one expert noted, “the only constant in the data industry is change” . Data leaders (CTOs, data engineers, etc.) should thus design architectures that are adaptable. That means favoring open standards (to avoid lock-in and leverage community innovation), keeping an eye on emerging tech but being cautious of hype, and above all focusing on what delivers value to the business with manageable complexity.
Closing Thoughts
The concept of the Modern Data Platform (or Modern Data Stack) encapsulates the dramatic shifts in data engineering over the past decade. We moved from slow, centralized warehouses to agile, cloud-based ecosystems that unlocked incredible analytical possibilities. This journey has been driven by ever-growing data demands and the imperative for businesses to become data-driven in real time. As we’ve discussed, the modern approach brought many benefits – scalability, democratization, faster innovation – but also introduced new challenges in complexity and maintainability.
For engineering leaders and CTOs, the key takeaway is that architecture decisions in the data platform space should be guided by the actual needs of the organization, not by buzzwords. Modern data platforms are powerful, but they are not one-size-fits-all. It’s important to critically evaluate each layer of your stack: Do we really need a separate tool for every function, or can we simplify? Are we prepared to handle the ops burden of a highly modular stack, or should we consider a more integrated platform? The “best” solution will differ if you’re a small startup or a large enterprise – but the principles of good data architecture (reliability, scalability, security, clarity) are universal.
We also saw that data architecture paradigms are evolving. Concepts like data mesh and data fabric remind us that technology is only one piece of the puzzle; how teams and data are organized is equally crucial. Embracing a data-driven culture might mean changing team structures or investing in governance and literacy as much as investing in tools.
Looking ahead, the future post-modern data platform promises to be more intelligent and less burdensome. Automation, AI, and integrated design will likely alleviate many of the pains of the first-generation modern stack. It’s an exciting time: the data platforms of 2025 and beyond will not only support business decisions but could be embedded at the core of business operations, reacting in real time and even proactively. They’ll likely be easier to use (perhaps conversationally, thanks to AI) and more reliable by default.
In conclusion, the modern data platform is not a fad – it’s a real step forward in how we harness data – but it’s also not a silver bullet. It requires thoughtful implementation and often a bit of skepticism to avoid the traps of hype. By learning from the origins and understanding the latest trends, engineering leaders can chart a path that leverages the modern data platform effectively, while steering clear of unnecessary complexity. The goal should always be enabling better decisions and products through data, with an architecture that is as elegant and simple as possible (but no simpler). As the technology continues to change, keeping that goal in focus will ensure your data platform remains an asset, not just an assembly of tools.
Sources
-
Atlan – “Modern Data Stack Explained: Past, Present & the Future” (2024): Discusses the definition and components of modern data platforms and the trends that led to their emergence .
-
- Atlan – “Adaptive Data Governance: Principles, Business Benefits & Successful Implementation Factors” (2024): Presents an adaptation of classical Data Governance, focused on being proactive and collaborative, in order to ensure Data Governance processes and policies evolve along with technology and regulatory needs.
-
Monte Carlo (Barr Moses) – “What Is a Data Platform and How Do You Build One?” (2024): Describes the six must-have layers of a modern data platform and the importance of treating data platforms as production-grade infrastructure .
-
Rivery (Itamar Ben Hemo) – “The Modern Data Stack Has to Evolve” (Feb 2024): A perspective on the over-modularity of the modern data stack and the need to shift towards a platform mindset for simplicity and efficiency .
-
DZone (Rahul) – “The Modern Data Stack Is Overrated — Here’s What Works” (Apr 2025): An opinion piece highlighting the complexity of typical modern stacks and advocating for leaner approaches with fewer tools and clearer ownership .
-
Chaos Genius – “Medallion Architecture 101 — Inside Bronze, Silver & Gold Layers” (2023): Explains the medallion (bronze/silver/gold) data layering pattern used in lakehouse architectures, comparing it with traditional ETL approaches .
-
Upsolver – “Batch vs Stream vs Microbatch Processing: A Cheat Sheet” (2021): Defines batch, streaming, and micro-batch processing, and when to use each approach, along with examples of frameworks and use cases .
-
Precisely – “Modern Data Architecture: Data Mesh and Data Fabric 101” (Oct 2024): Provides key takeaways on data mesh (decentralized, domain-driven ownership) versus data fabric (centralized, unified data management layer) and their benefits/challenges .
-
Atlan – “Data Mesh vs Data Fabric: Which Approach Fits Your Needs in 2024?” (Oct 2024): A detailed comparison between data mesh and data fabric, noting that data mesh focuses on people/process (decentralization) while data fabric focuses on technology (integration across environments) .
-
Data Engineering Weekly (Sundar Srinivas) – “Envisioning LakeDB: The Next Evolution of the Lakehouse Architecture” (2023): Article describing Google’s internal “Napa” system and the concept of “LakeDB”, a unified data management system that could integrate storage, ingestion, metadata, and querying for the next-gen data platform .
-
**Monte Carlo (Lindsay MacDonald) – “9 Trends Shaping the Future of Data Management in 2025” (Jun 2025):** Highlights emerging trends such as AI-driven data workflows, real-time analytics, adaptive governance, and data mesh adoption that are influencing the evolution of data platforms .