 Context is king. Image generated with gpt4o
Context is king. Image generated with gpt4o
A promising customer service bot, designed for seamless support, repeatedly faltered in production. It confidently provided inaccurate product availability, unable to access real-time inventory data, and collapsed when faced with multi-step user queries. Does this sound familiar? This scenario is common: a proof-of-concept excelling in demos but struggling under the dynamic pressures of a live environment, plagued by hallucinations and an inability to execute complex tasks. These failures highlight a critical gap between an LLM’s potential and its actual performance. The solution isn’t just better prompt-crafting, but a more fundamental discipline: Context Engineering. As AI thought leader Phil Schmid has argued, it is the number one job for agent builders—the strategic discipline for creating reliable, scalable, and high-ROI enterprise AI agents.
Why “Prompt Engineering” Isn’t Enough for the Enterprise
Remember the time of Prompt Engineering Craze?, when it seemed taming the AI beast was just about mastering this kind-of arcane magic. Now, for enterprise applications, prompt engineering alone is a tactical, reactive, and ultimately brittle approach. It treats the Large Language Model (LLM) as a static black box, where success depends on meticulously crafting the perfect set of hardcoded instructions. This method is fundamentally limited. As industry analyses note, prompt-centric strategies simply cannot scale to handle the dynamic, unforeseen queries of a real-world user base. The static nature of a prompt breaks down when confronted with constantly changing data or novel user intents.
The constraints are threefold: prompts are static, context windows are finite, and the approach fails to manage the dynamic information flow required for complex enterprise tasks. Derived to that timeliness of results referred to the moment of time the model was trained. Relying solely on prompt engineering is like giving a brilliant specialist a poorly written, outdated memo and expecting them to solve a complex, evolving problem. Context Engineering, in contrast, is giving that same specialist a live internet connection, a full library card, and a direct phone line to other experts—it equips them with the real-time, relevant resources needed to perform.
Context versus Prompt Engineering
They look like very close terms, but they are quite different concepts. Prompt engineering is the practice of crafting precise instructions or questions to guide an AI model’s behavior and outputs, while context engineering focuses on designing and supplying the relevant information (data, memory, tools, and retrieved knowledge) that the model needs to respond accurately and consistently. The key difference is that prompt engineering optimizes how you ask, whereas context engineering optimizes what the model knows at inference time; together, they address different sides of the same challenge—prompt engineering shapes intent, context engineering provides grounding. For more technical details see Context engineering article.
The Three Pillars of Context Engineering
To move beyond brittle prompts and build truly robust agents, builders must focus on architecting powerful context pipelines. This practice rests on three foundational pillars that ensure an agent has the right information, memory, and capabilities at the precise moment of need.
Pillar 1: Dynamic Data Retrieval
Effective agents require more than a static knowledge base; they need dynamic access to the right data. This means going beyond basic Retrieval-Augmented Generation (RAG). Advanced data retrieval involves a hybrid approach, combining keyword-based search with semantic vector search to find the most relevant information chunks. These retrieved chunks are then re-ranked for relevance before being fed to the LLM. Furthermore, enterprise data isn’t monolithic. A truly capable agent must source information from multiple types of data stores simultaneously—pulling structured data from SQL databases, unstructured text from policy documents, and live information from external APIs. For example, instead of reciting from a stale document, an agent can query a live database for product information or fetch real-time shipping updates from a logistics API. This multi-source retrieval, as highlighted by IBM’s work on information retrieval agents, is what allows an agent to synthesize a comprehensive and accurate response.
Pillar 2: Intelligent Memory Management
An agent that treats every interaction as its first is fundamentally limited. Intelligent memory management provides the continuity needed for coherent, personalized conversations. This requires distinguishing between short-term conversational memory and long-term entity memory. Short-term memory, often managed using techniques like conversational summary buffers, allows an agent to track the immediate back-and-forth of a dialogue. Long-term memory, as explored in courses from DeepLearning.AI, enables the agent to store and recall key facts about users, products, or other entities across multiple sessions. By storing user preferences or past support issues in a vector store, an agent can retrieve this long-term context to provide personalized recommendations or avoid asking repetitive questions, transforming a simple chatbot into a knowledgeable assistant.
Pillar 3: Precise Tool & Function Specifications
An agent’s ability to affect the real world is determined by the tools it can wield. However, an agent is only as good as its understanding of those tools. This is where precise tool and function specifications become critical. For an LLM to reliably use a tool—whether it’s get_order_status or process_refund—it needs an unambiguous definition of what the tool does, what inputs it requires, and what outputs it produces. Clear, descriptive docstrings and structured input/output schemas, using formats like Pydantic or JSON Schema, are essential. As outlined in research on structured outputs, this provides a clear contract that the LLM can follow. Equally important is robust error handling. If a tool fails or returns an unexpected result, the agent must be able to recognize the error, understand why it occurred, and attempt a corrective action, a process that frameworks like LangChain now explicitly support.
From a more engineering perspective, context engineering lies in four categories: write context (memory construction), select context (taking the information window for agent execution), compress context (just passing on the minimum needed tokens, that can rely on summarization, trimming, pruning etc.) and isolate context (especially useful when separating concerns in subtasks routed to different agents).
However context management isn’t free of troubles, negligent or poor management of it can lead to inconvenient situations as:
- Context poisoning when a hallucination makes it into the context
- Context distraction when the context overwhelm the training
- Context confusion when superfluous or spurious context influences the response
- Context clash when parts of it disagree
An umbrella concept
In literal words of LangChain: Context engineering as an umbrella that applies across a few different context types:
- Instructions – prompts, memories, few‑shot examples, tool descriptions, etc
- Knowledge – facts, memories, etc
- Tools – feedback from tool calls
Architecture in Action: Agentic RAG
Just to explain how it works, let’s take one of the most used and simple patterns when designing agent applications: Agentic RAG. As defined by IBM, Agentic RAG moves beyond simple data retrieval to create a cyclical reasoning loop that embodies Context engineering principles. This architecture allows a model to not just answer questions, but to plan, reason, and self-correct its way to a solution.
The flow follows a distinct, iterative loop: Plan → Retrieve → Augment → Act → Observe.
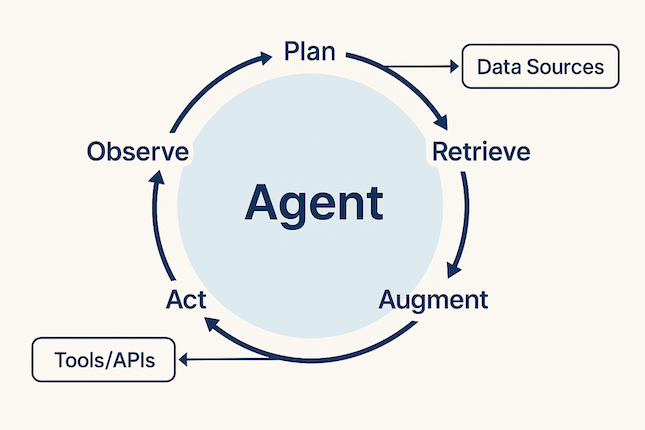
Cyclical flow of Agentic RAG: A central agent loops through Plan, Retrieve, Augment, Act, and Observe steps, interacting with Tools/APIs and Data Sources.Image generated with gpt4o
Consider a common customer query: “My last order was delayed, can I get a shipping update and a discount on my next purchase?“. A basic RAG system would likely fail. It might retrieve a document about the company’s discount policy but would be unable to check the order status or apply the discount. It lacks the ability to perform actions or synthesize information from multiple steps.
On the contrary, an agent built with Agentic RAG would handle this fluidly due to adding the proper context in the workflow:
-
Plan: The agent first deconstructs the request into two distinct parts: a request for a shipping update (requiring a tool) and a request for a discount (requiring policy information).
-
Retrieve & Act: It selects the
get_order_statustool, uses the customer’s ID to call the internal logistics API, and retrieves the real-time shipping information. -
Retrieve: Concurrently, it queries its knowledge base (Pillar 1) to find the company’s policy on compensation for delayed orders.
-
Augment & Act: It confirms the policy allows for a discount, selects the
apply_discount_coupontool (Pillar 3), and generates a unique coupon code for the user. -
Observe & Generate: The agent observes that both tasks are complete. It then synthesizes the shipping update, the retrieved policy information, and the newly generated discount code into a single, comprehensive response for the customer.
What we can see is the demonstration the system doesn’t just retrieve data but actively uses it to execute multi-step tasks, truly transforming a simple LLM into a capable enterprise agent. Turning simple and static instructions to a set of informed action plan.
However creating as thorough context could also bring about some challenges, due to its increased computing and storage cost, along with the model being bloated with superfluous information. So you need to streak the right balance between length and relevance (see a detailed analysis in the article King size - the bigger not the better).
Measuring the ROI of High-Quality Context
Translating these technical capabilities into tangible business value reveals the clear ROI of Context Engineering. When agents operate with high-quality, real-time context, they become more reliable, efficient, and trusted by users. This directly impacts the bottom line. Industry observations from early pilots, as noted by IBM, show that context-rich agents can lead to 30-50% drops in escalations to human support staff. As analyses on chatbot ROI demonstrate, these improvements in reliability and capability are the primary drivers of value in successful enterprise AI deployments.
The key business benefits of setting the right contextual data are clear and measurable:
-
Reliability & Uptime: With accurate data and robust error handling, agents fail less often, leading to more consistent and dependable performance.
-
Cost Reduction: Fewer hallucinations and higher task completion rates directly lower the costs associated with agent supervision and manual escalations.
-
Increased User Trust & CSAT: Users who receive correct, relevant, and fast answers are more satisfied. This builds trust in automated systems and significantly improves overall customer satisfaction (CSAT).
-
Enhanced Capabilities: Agents can finally handle the complex, multi-step tasks that were previously the exclusive domain of human employees, unlocking new efficiencies and revenue opportunities.
Final thoughts
The path to production-ready AI agents is not paved with clever prompt tweaks. It is built on a robust foundation of dynamic context pipelines. The era of prompt engineering as a primary strategy is over; the future of reliable AI lies firmly in Context Engineering. For product owners, solution architects, and AI platform teams, the mandate is clear: stop fine-tuning words and start engineering your agent’s access to information.
To begin this crucial shift, here are three actionable next steps:
-
Audit Your Context: Map the critical data sources, memory requirements, and essential tools your agent needs to perform its core functions reliably. Compare this ideal map with what it currently has access to, identifying the most critical gaps and areas for improvement.
-
Prototype an Agentic complete Loop: Using a framework like LangChain, Crewai, start building a small-scale agent that implements the Plan-Retrieve-Act pattern. Start with one tool and one data source to prove the model’s effectiveness and understand the iterative process.
-
Measure and Iterate: Define a key performance metric—such as hallucination rate, task completion rate, or escalation frequency. Measure this baseline before implementing changes, then apply your context improvements, and rigorously track the delta to prove the tangible value of your new, context-rich approach.
Using the right combination of agent workflow structure, instructions and context, allows to build of next generation of enterprise AI agents—agents that don’t just talk, but act, solve, and deliver measurable business value, transforming your operations.
Further readings
The New Skill in AI is Not Prompting, It’s Context Engineering LangChain docs Context Engineering