 Context is everything. Image generated with gpt4o
Context is everything. Image generated with gpt4o
Picture this: Roast-Rite, a fast-growing e-commerce coffee brand, launches a shiny chatbot to handle customer questions during its annual “Bean-anza” sale. The dev team spends days perfecting a single prompt:
“You are a helpful support agent for Roast-Rite. Answer questions about orders, products, and shipping policies in a friendly tone.”
During internal tests it works fine, so they ship it. But, on launch night, Isabella, a loyal customer, types:
“Hey! I bought the Colombia Aurora beans last month. Can I still get the 20-% loyalty discount if I order two five-pound bags today and have them shipped to Lisbon?”
The bot cheerfully replies:
“Absolutely! All Colombian beans ship free worldwide, and your 20 % discount applies automatically.”
Sounds great—but it’s dead wrong. The free-shipping promo ended yesterday, Aurora isn’t in the loyalty program, and Roast-Rite doesn’t even ship five-pound bags to Portugal. Within two hours, Twitter fills with screenshots, support lines jam, and finance estimates a five-figure revenue leak.
What went wrong? The prompt was “polite and clear,” but the model had zero access to real-time pricing tables, promo rules, inventory data, or Isabella’s purchase history. It hallucinated a perfect-sounding answer because that’s all it could do. Prompt engineering alone hit its ceiling.
So the ops team calls an emergency stand-up. Instead of rewriting the prompt yet again, they thought, why not giving the agent additional information about the question. Let’s give a proper context to the model, in order words to engineer the context around the model:
- System layer adds a rule: “Always ground answers in live catalog and promo APIs. If data is missing, ask follow-up questions.”
- Dynamic retrieval (RAG) pulls the latest discount matrix and shipping rules for the queried SKU.
- User profile memory injects Isabella’s order history so the bot knows she bought a 12-oz bag last month.
- Tool invocation schema lets the model call a checkShipping(destination, weight) function before committing to an answer.
The prompt stays almost identical, but the context window now brims with facts. Isabella types the same question. The upgraded bot responds:
“I can get those beans to Lisbon, but five-pound bags exceed our EU weight limit. A pair of 2-lb bags ships for €9, and your loyalty tier gives you 10 % off, not 20 %. Want me to add them to your cart?”
No more hallucinations, no revenue leak, and the customer feels heard. The hero wasn’t a clever prompt—it was context engineering.
So, what’s context engineering?
Think of prompt engineering as writing the question, and context engineering as setting the stage so the AI can answer properly. Formally, context engineering is the deliberate design, assembly, and governance of every piece of information—static or live—that an AI model sees at inference time: instructions, user state, retrieved documents, tool outputs, memory, and guardrails. When done well, it turns a “smart autocomplete” into a reliable coworker. Industry analysts call it “the new foundation of modern AI system design”. Andrej Karpathy thinks of LLM as a new type of (operating system](https://www.youtube.com/watch?si=-aKY-x57ILAmWTdw&t=620&v=LCEmiRjPEtQ&feature=youtu.be&ref=blog.langchain.com) in which the model is the CPU, while the RAM is its context window, in his own words:
[Context engineering is the] ”…delicate art and science of filling the context window with just the right information for the next step.”
It complements prompt engineering rather than replacing it:
| Prompt Engineering | Context Engineering |
|---|---|
| Asks the right question | Supplies the right knowledge |
| Single-turn focus | Multi-turn, stateful focus |
| Tweaks wording & personas | Orchestrates data retrieval, memory, tools |
| Limited by what fits in the prompt | Extends model’s reach beyond native training |
Without a good prompt, the model may misunderstand intent; without good context, it may answer confidently yet incorrectly. You need both.
Similar but not quite the same
Prompt engineering is the practice of crafting precise instructions or questions to guide an AI model’s behavior and outputs, while context engineering focuses on designing and supplying the relevant information (data, memory, tools, and retrieved knowledge) that the model needs to respond accurately and consistently. The key difference is that prompt engineering optimizes how you ask, whereas context engineering optimizes what the model knows at inference time; together, they address different sides of the same challenge—prompt engineering shapes intent, context engineering provides grounding.
Five Ways to provide context
There are some forms to shape the context needed for the language model. Below I will mention the five most used mechanisms (also the simplest). Since it is constantly evolving though, most likely the moment you’re reading this it, you wold find a couple more:
-
Retrieval-Augmented Generation (RAG): Pipeline that fetches relevant docs from a knowledge base, appends snippets to the model, and cites sources. Great for customer support, policy Q&A, and any domain where freshness matters. AWS notes RAG is often cheaper than retraining a model and dramatically cuts hallucinations.
-
Long Context Windows: Newer LLMs swallow 100 K-plus tokens—whole contracts, codebases, or books—in one go. Perfect for analytic tasks where chunking could miss cross-references. But IBM reminds us that more tokens mean more cost and potential “information overload.”
-
Contextual Retrieval & Re-Ranking: Anthropic’s “Contextual Retrieval” prepends mini-summaries to every chunk so embeddings understand what they reference, slashing failed look-ups by up to 67 %.
-
Memory Buffers & Summaries: For chatbots and copilots, a short-term memory keeps recent turns handy, while a long-term store (often a vector DB) saves user preferences or project history. Summaries compress it all so the context window never bursts.
-
Tool Schemas & Function Calling: Instead of stuffing data into text, let the model call APIs (checkShipping, fetchBalance) and pipe the results back into context. This keeps prompts lean and answers grounded in real systems.
An umbrella concept
As of LangChain docs: Context engineering as an umbrella that applies across a few different context types:
- Instructions – prompts, memories, few‑shot examples, tool descriptions, etc
- Knowledge – facts, memories, etc
- Tools – feedback from tool calls
A very nice guide for context engineering is the LangChain’s docs devoted to this question, in that guide they classify this topic in 4 areas:
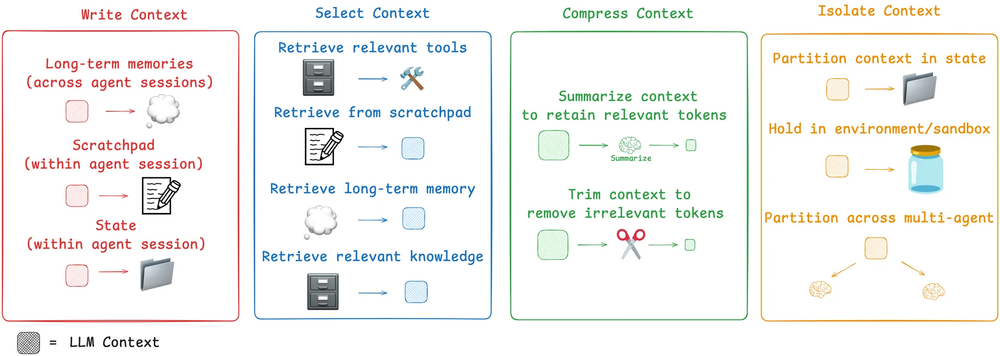 General categories of context engineering. Source: Langchain
General categories of context engineering. Source: Langchain
- Write context, where historical memories are stored, with different degrees of structure and time length: long term memories, scratch pads (notes within the session) or as state.
- Select context, it means to take only the relevant parts. Its application depends on how the previous point is done, for memories you can select a few shot examples (episodic memories or past agent actions), as a set instructions (procedural memories, as former system or instruction prompts) or a bundle of facts (semantic memories as a set of facts of the user/agent). It’s common the use of specialized databases like knowledge graphs in order to make this task easier.
- Compress context, a growing number of input tokens impacts in cost an performance. Therefore a proper optimization of window size is key to save money along with preventing distraction in the generation due to superfluous data in the agent’s memories. Particularly in the cases when agents run hundred of turns, like we can see in common chat session. Oddly enough, a more concise context will reduce the likelihood of having contradicting memory pieces, or distracting ones. Techniques here most use are summarization or trimming.
- Isolate context, in the case you can split the task in several agents specialized in different aspects of the problem. This is very common in multi-agent architectures (for example deep research implementations, see the article for Anthropic’s implementation), where tasks are divided in concerns (a core feature in OpenAI’s Swarm library) run in parallel for a further agent that consolidates the results.
Limitations and Watch-Outs
Introducing context in the agentic applications and chatbots is great to make them better, but they are not free of drawbacks. It’s evident that passing on more input to the model, it will turn into more cost, latency and risks:
-
Context rot: Chroma’s July 2025 study shows many models degrade as prompts exceed mid-window length, even with fancy architectures. Quality, not just quantity, of context matters.
-
Cost & latency: Big windows and chunky RAG responses run up token bills and slow replies. Engineering teams must budget tokens like real money.
-
Security: More context means more attack surface—prompt injection, retrieval poisoning, leaking PII. Sanitization layers and strict access controls are non-negotiable.
-
Maintenance overhead: Knowledge bases grow stale; tools change schemas; memory may accumulate junk. Treat context pipelines like products: version them, monitor them, refactor them.
Context management problems
This activity is not free of troubles, there are some situations that cause undesired effects. Not only due to poor management of data but also because an excess of information:
- Context poisoning when a hallucination makes it into the context
- Context distraction when the context overwhelm the training.
- Context confusion when superfluous or spurious context influences the response. See this example from Simon Willison blog, in which chatgpt wrongly put in his location information in a image generation.
- Context clash when parts of it disagree
The View from 30,000 Feet
On the one hand, prompt engineering means to ask better questions, on the other hand context engineering teaches us to hand the AI everything it needs to answer responsibly—live data, memories, tools, and guardrails—every single time.
Back at Roast-Rite, the team now thinks of their bot like a new hire: train it (prompt), give it the company wiki (retrieval), wire up the cash register (tools), and keep its notebook tidy (memory). Do that, and the AI stops guessing and starts working. A short bunch of takeways would be:
-
If your model keeps hallucinating, your context is probably the culprit.
-
Start small: wire one reliable data source into a RAG loop and measure the drop in errors.
-
Budget tokens like dollars; compress and rank ruthlessly.
-
Treat context pipelines as living software—log them, test them, update them.
-
Great prompts open the door; great context sets the table.